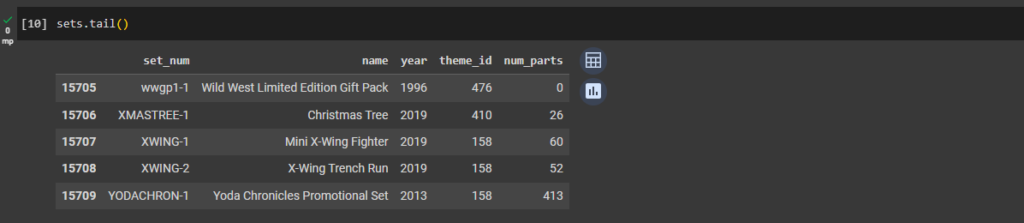
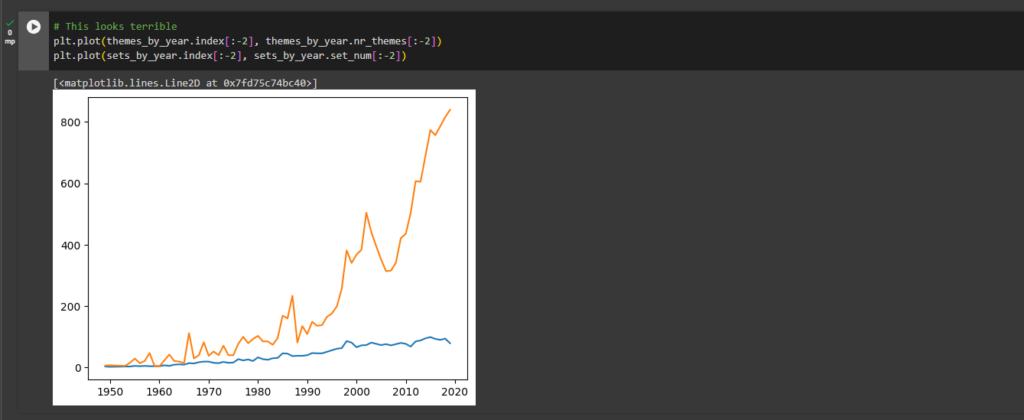
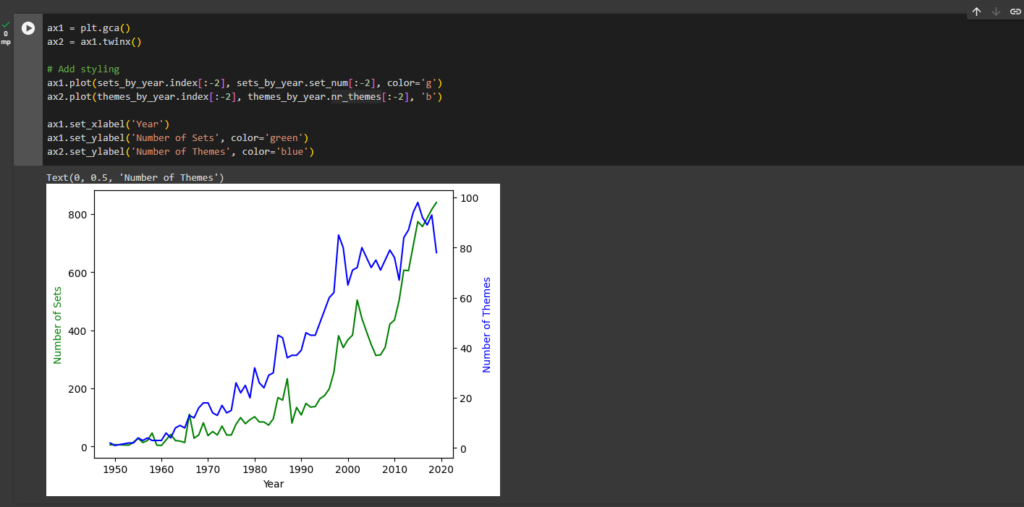
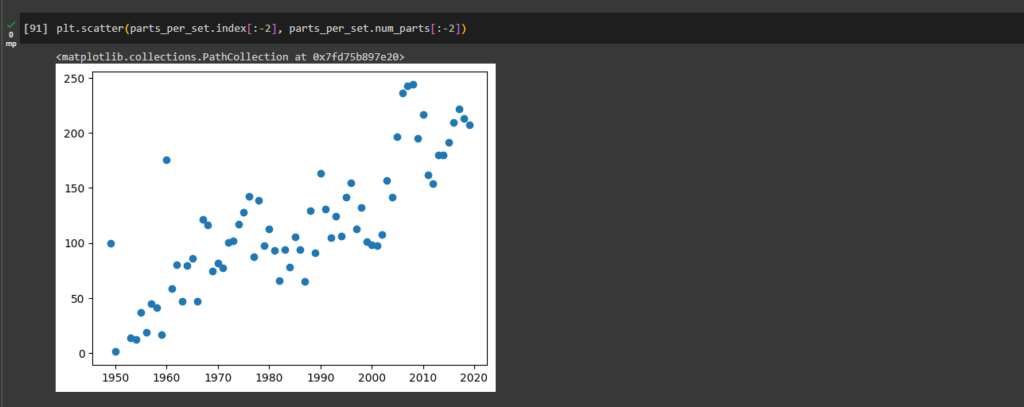
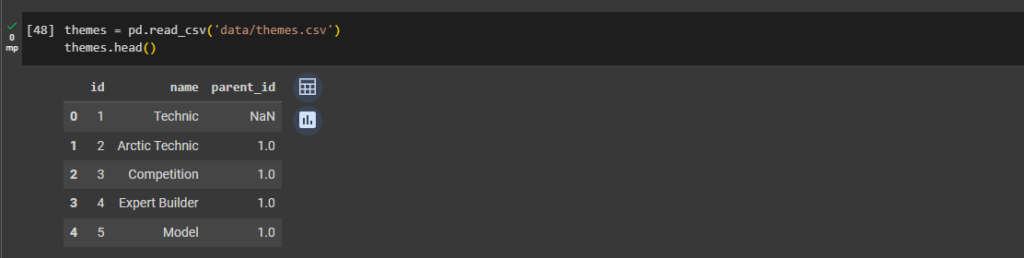
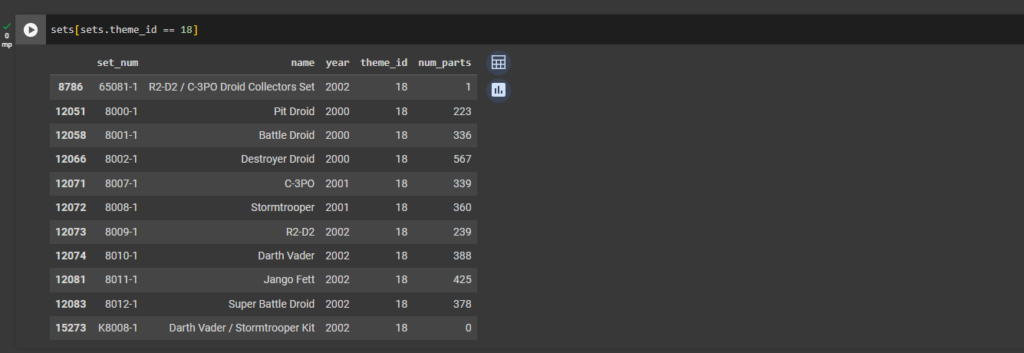
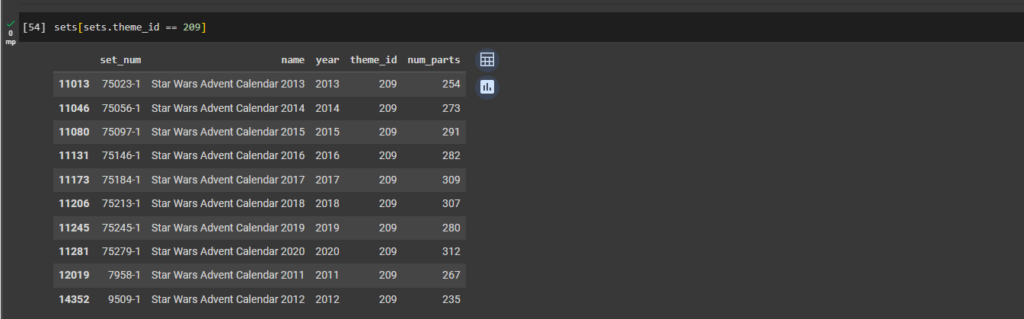
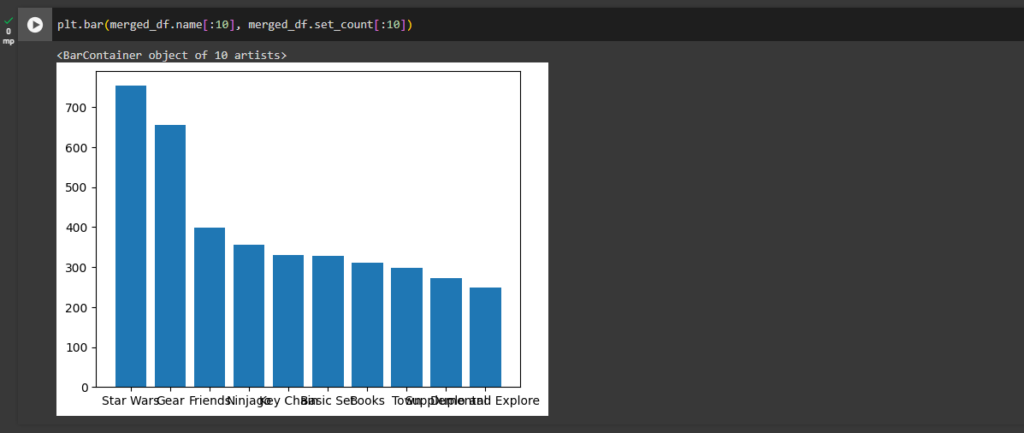
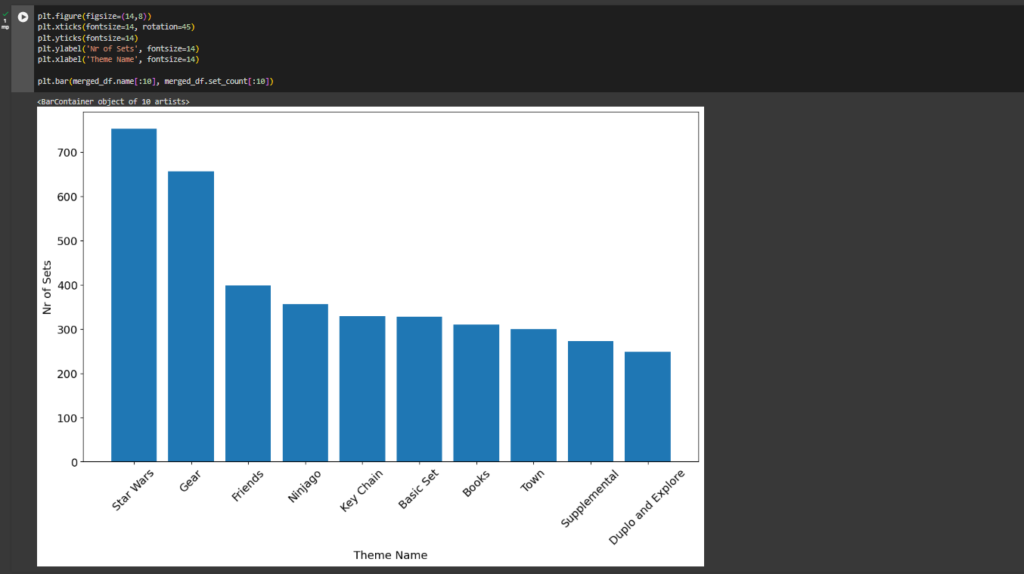
ax1 = plt.gca()
ax2 = ax1.twinx()
# Add styling
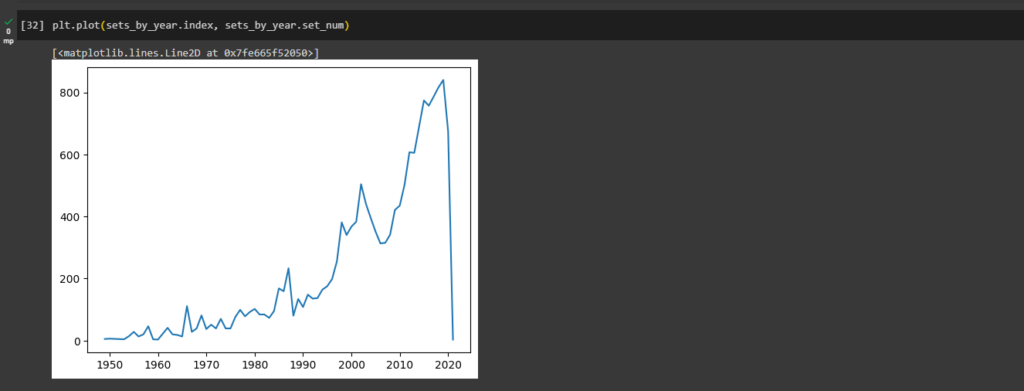
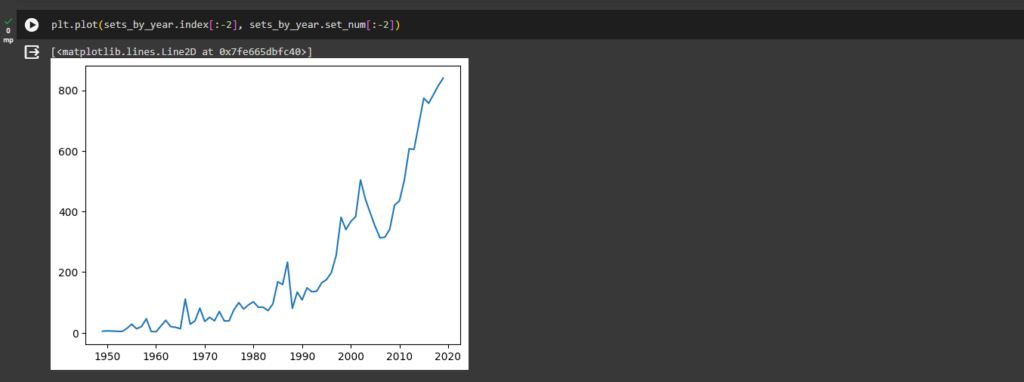
ax1.plot(sets_by_year.index[:-2], sets_by_year.set_num[:-2], color='g')
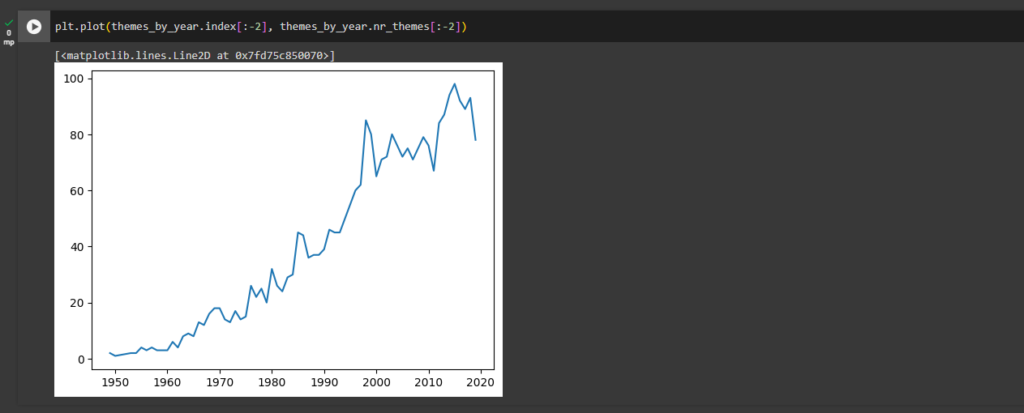
ax2.plot(themes_by_year.index[:-2], themes_by_year.nr_themes[:-2], 'b')
ax1.set_xlabel('Year')
ax1.set_ylabel('Number of Sets', color='green')
ax2.set_ylabel('Number of Themes', color='blue')